funcmain() { d := Dog{} c := Cat{} makeSound(d) // 输出 "Woof!" makeSound(c) // 输出 "Meow!" }
Go interface 的实现原理
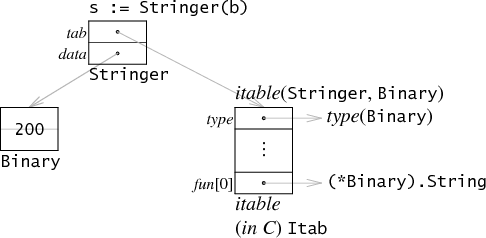
interface 在 Go 语言的实现其实就靠一个叫做 iface 的数据结构。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
type iface struct { tab *itab data unsafe.Pointer // 数据指针 }
type itab struct { inter *interfacetype _type *_type hash uint32// copy of _type.hash. Used for type switches. _ [4]byte fun [1]uintptr// variable sized. fun[0]==0 means _type does not implement inter. }
type TypeAssert struct { Cache *TypeAssertCache Inter *InterfaceType CanFail bool } type TypeAssertCache struct { Mask uintptr Entries [1]TypeAssertCacheEntry } type TypeAssertCacheEntry struct { // type of source value (a *runtime._type) Typ uintptr // itab to use for result (a *runtime.itab) // nil if CanFail is set and conversion would fail. Itab uintptr }
type InterfaceType struct { Type PkgPath Name // import path Methods []Imethod // sorted by hash }
type _type = abi.Type // 就是上面的 Type 类型
// typeAssert builds an itab for the concrete type t and the // interface type s.Inter. If the conversion is not possible it // panics if s.CanFail is false and returns nil if s.CanFail is true. functypeAssert(s *abi.TypeAssert, t *_type) *itab { var tab *itab if t == nil { if !s.CanFail { panic(&TypeAssertionError{nil, nil, &s.Inter.Type, ""}) } } else { tab = getitab(s.Inter, t, s.CanFail) }
if !abi.UseInterfaceSwitchCache(GOARCH) { return tab }
// Maybe update the cache, so the next time the generated code // doesn't need to call into the runtime. if cheaprand()&1023 != 0 { // Only bother updating the cache ~1 in 1000 times. return tab } // Load the current cache. oldC := (*abi.TypeAssertCache)(atomic.Loadp(unsafe.Pointer(&s.Cache)))
if cheaprand()&uint32(oldC.Mask) != 0 { // As cache gets larger, choose to update it less often // so we can amortize the cost of building a new cache. return tab }
// Make a new cache. newC := buildTypeAssertCache(oldC, t, tab)
// Update cache. Use compare-and-swap so if multiple threads // are fighting to update the cache, at least one of their // updates will stick. atomic_casPointer((*unsafe.Pointer)(unsafe.Pointer(&s.Cache)), unsafe.Pointer(oldC), unsafe.Pointer(newC))
return tab }
funcgetitab(inter *interfacetype, typ *_type, canfail bool) *itab { iflen(inter.Methods) == 0 { throw("internal error - misuse of itab") }
// easy case if typ.TFlag&abi.TFlagUncommon == 0 { if canfail { returnnil } name := toRType(&inter.Type).nameOff(inter.Methods[0].Name) panic(&TypeAssertionError{nil, typ, &inter.Type, name.Name()}) }
var m *itab
// First, look in the existing table to see if we can find the itab we need. // This is by far the most common case, so do it without locks. // Use atomic to ensure we see any previous writes done by the thread // that updates the itabTable field (with atomic.Storep in itabAdd). t := (*itabTableType)(atomic.Loadp(unsafe.Pointer(&itabTable))) if m = t.find(inter, typ); m != nil { goto finish }
// Not found. Grab the lock and try again. lock(&itabLock) if m = itabTable.find(inter, typ); m != nil { unlock(&itabLock) goto finish }
// Entry doesn't exist yet. Make a new entry & add it. m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.Methods)-1)*goarch.PtrSize, 0, &memstats.other_sys)) m.inter = inter m._type = typ // The hash is used in type switches. However, compiler statically generates itab's // for all interface/type pairs used in switches (which are added to itabTable // in itabsinit). The dynamically-generated itab's never participate in type switches, // and thus the hash is irrelevant. // Note: m.hash is _not_ the hash used for the runtime itabTable hash table. m.hash = 0 m.init() itabAdd(m) unlock(&itabLock) finish: if m.fun[0] != 0 { return m } if canfail { returnnil } // this can only happen if the conversion // was already done once using the , ok form // and we have a cached negative result. // The cached result doesn't record which // interface function was missing, so initialize // the itab again to get the missing function name. panic(&TypeAssertionError{concrete: typ, asserted: &inter.Type, missingMethod: m.init()}) }
// init fills in the m.fun array with all the code pointers for // the m.inter/m._type pair. If the type does not implement the interface, // it sets m.fun[0] to 0 and returns the name of an interface function that is missing. // It is ok to call this multiple times on the same m, even concurrently. func(m *itab) init() string { inter := m.inter typ := m._type x := typ.Uncommon()
// both inter and typ have method sorted by name, // and interface names are unique, // so can iterate over both in lock step; // the loop is O(ni+nt) not O(ni*nt). ni := len(inter.Methods) nt := int(x.Mcount) xmhdr := (*[1 << 16]abi.Method)(add(unsafe.Pointer(x), uintptr(x.Moff)))[:nt:nt] j := 0 methods := (*[1 << 16]unsafe.Pointer)(unsafe.Pointer(&m.fun[0]))[:ni:ni] var fun0 unsafe.Pointer imethods: for k := 0; k < ni; k++ { i := &inter.Methods[k] itype := toRType(&inter.Type).typeOff(i.Typ) name := toRType(&inter.Type).nameOff(i.Name) iname := name.Name() ipkg := pkgPath(name) if ipkg == "" { ipkg = inter.PkgPath.Name() } for ; j < nt; j++ { t := &xmhdr[j] rtyp := toRType(typ) tname := rtyp.nameOff(t.Name) if rtyp.typeOff(t.Mtyp) == itype && tname.Name() == iname { pkgPath := pkgPath(tname) if pkgPath == "" { pkgPath = rtyp.nameOff(x.PkgPath).Name() } if tname.IsExported() || pkgPath == ipkg { ifn := rtyp.textOff(t.Ifn) if k == 0 { fun0 = ifn // we'll set m.fun[0] at the end } else { methods[k] = ifn } continue imethods } } } // didn't find method m.fun[0] = 0 return iname } m.fun[0] = uintptr(fun0) return"" }
// interfaceSwitch compares t against the list of cases in s. // If t matches case i, interfaceSwitch returns the case index i and // an itab for the pair <t, s.Cases[i]>. // If there is no match, return N,nil, where N is the number // of cases. funcinterfaceSwitch(s *abi.InterfaceSwitch, t *_type) (int, *itab) { cases := unsafe.Slice(&s.Cases[0], s.NCases)
// Results if we don't find a match. case_ := len(cases) var tab *itab
// Look through each case in order. for i, c := range cases { tab = getitab(c, t, true) if tab != nil { case_ = i break } }
if !abi.UseInterfaceSwitchCache(GOARCH) { return case_, tab }
// Maybe update the cache, so the next time the generated code // doesn't need to call into the runtime. if cheaprand()&1023 != 0 { // Only bother updating the cache ~1 in 1000 times. // This ensures we don't waste memory on switches, or // switch arguments, that only happen a few times. return case_, tab } // Load the current cache. oldC := (*abi.InterfaceSwitchCache)(atomic.Loadp(unsafe.Pointer(&s.Cache)))
if cheaprand()&uint32(oldC.Mask) != 0 { // As cache gets larger, choose to update it less often // so we can amortize the cost of building a new cache // (that cost is linear in oldc.Mask). return case_, tab }
// Make a new cache. newC := buildInterfaceSwitchCache(oldC, t, case_, tab)
// Update cache. Use compare-and-swap so if multiple threads // are fighting to update the cache, at least one of their // updates will stick. atomic_casPointer((*unsafe.Pointer)(unsafe.Pointer(&s.Cache)), unsafe.Pointer(oldC), unsafe.Pointer(newC))
return case_, tab }
源代码虽然有点长,但是稍微耐心点是很容看懂的。
最关键的是要理解 func getitab(inter *interfacetype, typ *_type, canfail bool) *itab 这个函数在做什么。
它尝试从 interface type 和 struct type 里构造出一个 itab,如果能构造成功,那么就意味着这个 struct 实现了该 interface。
// TypeOf returns the reflection Type that represents the dynamic type of i. // If i is a nil interface value, TypeOf returns nil. funcTypeOf(i interface{}) Type { eface := *(*emptyInterface)(unsafe.Pointer(&i)) return toType(eface.typ) }
// toType converts from a *rtype to a Type that can be returned // to the client of package reflect. In gc, the only concern is that // a nil *rtype must be replaced by a nil Type, but in gccgo this // function takes care of ensuring that multiple *rtype for the same // type are coalesced into a single Type. functoType(t *abi.Type) Type { if t == nil { returnnil } return toRType(t) }
// ValueOf returns a new Value initialized to the concrete value // stored in the interface i. ValueOf(nil) returns the zero Value. funcValueOf(i any) Value { if i == nil { return Value{} } return unpackEface(i) }
// unpackEface converts the empty interface i to a Value. funcunpackEface(i any) Value { e := (*emptyInterface)(unsafe.Pointer(&i)) // NOTE: don't read e.word until we know whether it is really a pointer or not. t := e.typ if t == nil { return Value{} } f := flag(t.Kind()) if ifaceIndir(t) { f |= flagIndir } return Value{t, e.word, f} }