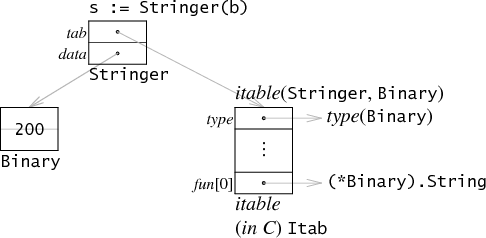
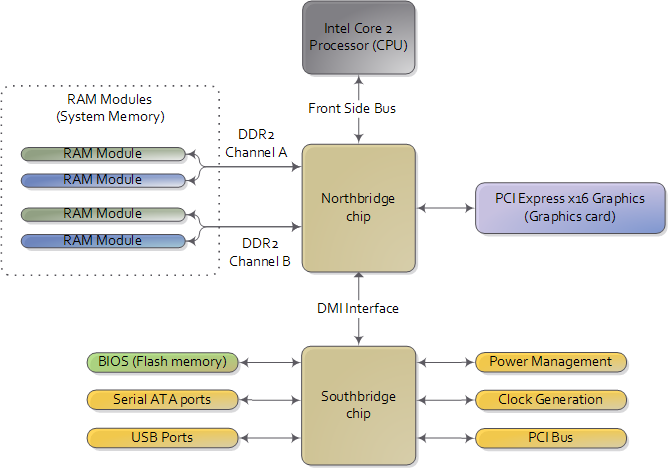
这篇文章我主要来谈谈 Linux 中各种内存指标之间的关系,我在下面画了一个简单的关系图。
正如标题所示,这是一篇 work-in-progress 的文章,也就意味:
- 有很多地方需要补充的地方,比如说 swap 和内存回收的部分;
- 有些地方没有足够的铺垫,比如说 cgroup、cadvisor、mmap 等;
- 有些地方排版不好看,后续还需要调整;
- 还没有来得及很详细地核对,请在阅读本文的时候保持怀疑;
注意:以下我们都先忽略 swap
free 命令
free 命令用来展示总共的、使用掉的、未被使用的物理内存和 swap 内存的大小,以及被内核所使用的 buffer 和 cache 内存的大小。这些信息都是从 /proc/meminfo 中收集而来的。
执行 free 命令,会输出:
1 | total used free shared buff/cache available |
执行 free -h 可以输出人类可读的格式,:
1 |
|
Mem表示物理内存,Swap 表示 swap 区(swap 文件)的内存。total所有内存 (MemTotal and SwapTotal in/proc/meminfo)used使用掉的内存,等于 total - free - buffers - cachefree未被使用的内存 (MemFree and SwapFree in/proc/meminfo)shared进程间共享内存,绝大部分都是 tmpfs,因为其他进程可以访问 tmpfs 驻留在内存中区域,所以这部分也属于共享内存。(Shmem in /proc/meminfo, kernels 2.6.32 以上支持, 如果不支持就展示为 0。)buff/cache等于 buffer + cache,这部分都是内核使用掉的内存。- buff 内核缓存 (Buffers in
/proc/meminfo) - cache 页缓存 + slab (Cached and Slab in
/proc/meminfo)- page cache 就是页缓存;
- slab 是 slab allocator 分配给内存,这部分内存是给内核使用的;
- buff 内核缓存 (Buffers in
available估计启动一个新应用所能用的内存大小,这个大小不包含 swap 的区域,等于 free + buff + cache。这是大概的估计值,因为 cache 不可能都被释放掉给该应用使用,只有部分可以释放掉。(MemAvailable in /proc/meminfo, kernels 3.14 以上支持,kernels 2.6.27+ 中模拟出该数值,其他版本下则该值和 free 相等。)
/proc/meminfo 详解
我的 linux 版本:uname: Linux wgv-opsk8smanager-02 3.10.0-514.26.2.el7.x86_64 #1 SMP Tue Jul 4 13:29:22 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
cat /proc/meminfo 可以查出当前各种内存指标,这里面指标非常多。
我查看官方文档的说明,如下:
1 | Provides information about distribution and utilization of memory. This varies by architecture and compile options. The following is from a 16GB PIII, which has highmem enabled. You may not have all of these fields. |
对此,我翻译成中文:
1 | MemTotal: 32780396 kB // free 里的 total |
各种内存之间的关系图
以我自己的理解所绘制的这些内存指标的关系图(A–>B 指 A 完全被 B 包含):

说明:
- 物理内存 = 内核代码占用的内存 + 少量预留内存 + 那一大堆内存
- 那一大堆内存 = 空闲的内存 + Slab 内存(只有内核本身会用这部分)+ 内核栈 + 页表本身 + 内存黑洞 + 匿名页内存 + 缓存 Cached(一般情况下我们只需要关心最后两个,前面都是内核涉及的部分)
- 匿名页内存 = 活跃的匿名页内存 + 不活跃的匿名页内存,这其中包括了普通大小的匿名页内存和大页匿名内存(如果开启大页的话)
- 缓存 Cached = 活跃的文件缓存 + 不活跃的文件缓存 + 共享缓存(也就是 tmpfs 文件系统的大小)
- 活跃的内存 = 活跃的匿名页内存 + 活跃的文件缓存
- 不活跃的内存 = 不活跃的匿名页内存 + 不活跃的文件缓存
- 共享缓存 = 实际上就是 tmpfs 文件系统的大小 = 包括了通过 mmap 共享的内存、进程间通信使用到的内存、动态库等等,这部分是用户程序控制的,内核没有权利去回收或者做别的操作。
- Mapped = mmap 中文件映射的部分,被全部包含在 Cached 里
什么是匿名页缓存?匿名页缓存就是没有对应的文件的内存,实际上就是堆栈内存。
什么是页缓存?页缓存和匿名页缓存相反,就是有文件对应的内存,可以被放回到文件里的内存。
cgroups memory stat
接下来我们看看 cgroup 级别的内存统计指标,这些指标都存在 /sys/fs/cgroup/memory 下。
这里要先做一个关于 cgroup 的铺垫,可以把 cgroup 理解为是一个树形结构,一个 cgroup 下面可以包含多个子 cgroup,子 cgroup 有可以包含多个子 cgroup。
这个路径下有一个文件叫做 memory.stat,包含了 per-cgroup memory local state
cadvisor 里的关于内存的指标
接触过监控系统的人应该有所耳闻,可以通过 cadvisor 这个采集器来收集容器里的很多指标数据,比如说网络、内存、CPU 等等。
cadvisor 中关于内存的很多指标都来自于 /sys/fs/cgroup/memory 下的 /sys/fs/cgroup/memory/memory.stat。
cadvisor 里某些监控指标的来源:
- container_memory_rss = total_rss (来源于 memory.stat)
- container_memory_usage_bytes = container_memory_rss + container_memory_cache + kernel memory(某些情况会被统计进入),也就等于 anonymous cache + swap cache + page cache + kernel memory = /sys/fs/cgroup/memory/memory.usage_in_bytes
- container_memory_working_set_bytes = container_memory_usage_bytes (这个值可以直接读 /sys/fs/cgroup/memory/memory.usage_in_bytes 取到) - total_inactive_file(因为不活跃的文件页缓存优先被回收,所以就不算进这个指标里)
mmap 、共享内存和 tmpfs (todo 这一段还需要再打磨一下)
mmap 是一个 libc 函数,底层实现也是一个叫 mmap 的系统调用。库函数签名:
1 | void * mmap(void *addr,size_t length, int prot, int flags, int fd,off_t offset) |
mmap 的作用是把进程的虚拟内存和某一段物理内存建立映射,这里的物理内存当然可以是匿名内存。mmap 的实现原理是建立页表。参数里面的 fd 指的是 linux 的虚拟文件系统的文件,当然可以是 tmpfs 的 fd,这也是 mmap 共享内存的实现方式。
mmap 是实现共享内存的一种方式,他们相互之间不存在包含关系,所以,mmap 中只有共享内存的部分会被统计到上述的“共享内存”里。
在 Linux 里,所有的共享内存都是通过 tmpfs 来实现的,包括 POSIX 共享内存和 SystemV 共享内存。
tmpfs 是 Linux 的一种虚拟机文件系统,这种虚拟文件都是在内存里的,也就是说,如果你创建一个 10GB 的 tmpfs 类型的文件,那么物理内存就会被用掉 10GB。(使用 shm_open 创建一个共享内存文件描述符。)然后再用 mmap 把 shm_open 出来的文件映射到进程虚拟内存里,那么就通过 mmap 进行了共享内存。
很显然,mmap 部分的内存是不可以被回收的,因为这本质上不是系统管理的缓存,而是进行由进程自己负责的内存。
注意:/proc/meminfo 里的 Mapped 字段,表示的只是 files which have been mmaped, such as libraries,意思是 mmap 中的文件映射的部分(不包括匿名映射的部分),而且这部分一定是经过页缓存的,所以一定被算在 Cached 里的。
以上统计数据比较复杂的地方在于,各种统计项之间有包含关系,也有部分重叠关系,只有理清楚这些的关系,我们在利用这些数据进行监控时,才能做到有依据、不缺少、不重复。